Python 教程
认识Python
python2 filename.py;python3 filename.py
python2默认不支持中文
python3支持中文,优先使用python3,未来和主流版本
Python2.7,2最终版本,支持python2和支持部分python3,属于过渡版本
PyCharm 集成开发环境
Python基础
变量和简单数据类型
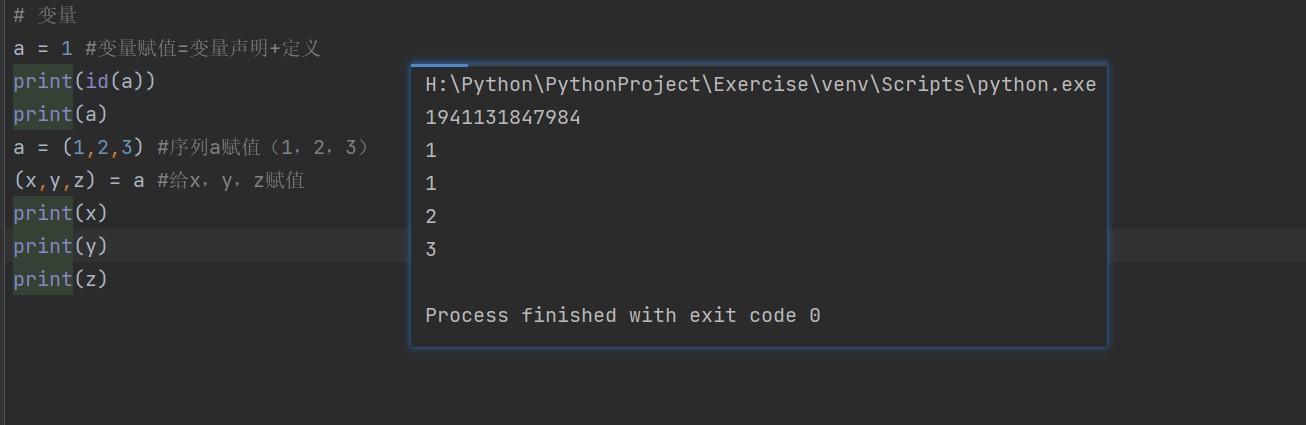
变量
变量与常量
变量是存储在计算机内存里的一块区域,值可变,常量是一块只读的内存区域,一旦赋值不可改变。
- 变量不需要声明,直接赋值,即赋值包括声明+定义过程
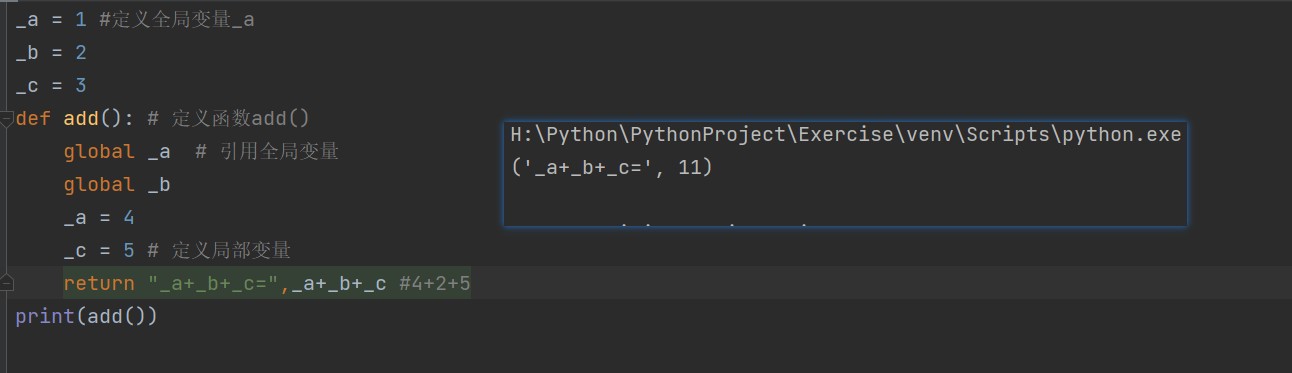
全局变量一般定义在函数外
局部变量
在函数或代码块内使用,函数外无法调用函数内局部变量
常量
数 Number
- Python3 支持int(长整型)、float、bool、complex(复数)
- python3 没有python2的long类型,python2没有布尔型,用0表示False,用1表示True

注释
- 规范对模块,函数,方法和行内注释
- ①单行注释 #②多行注释三个单引号
'''或三个双引号"""
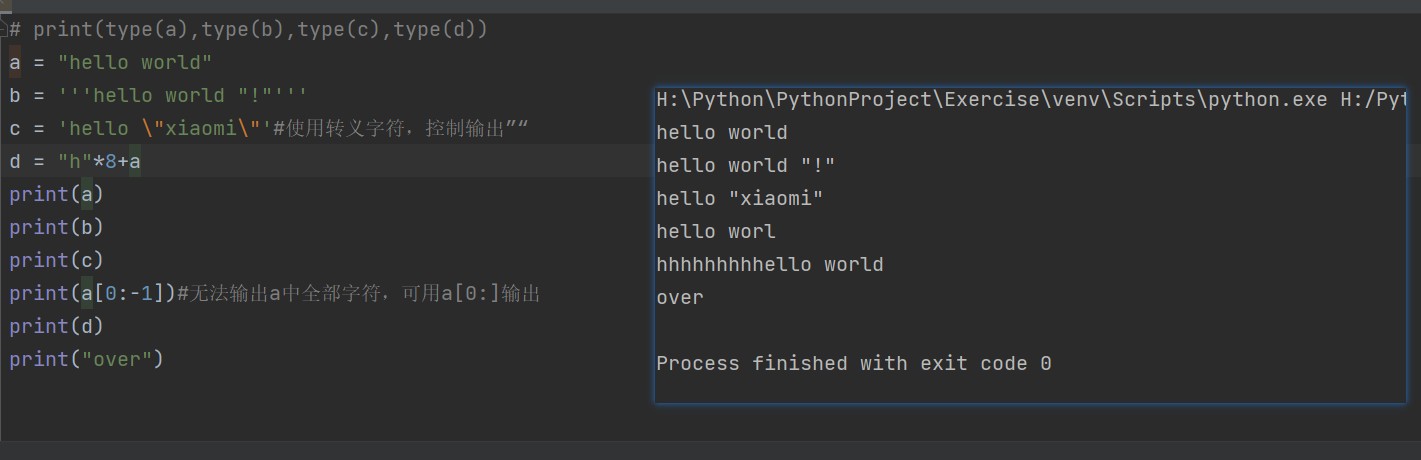
字符串 String
- 字符串用单引号
'或者双引号",使用\转义特殊字符 - 三引号
'''可以控制输出单引号,双引号和特殊字符 - 使用
r可以让反斜杠不发生转义,字符串可以用+运算符连接在一起,用*运算符重复 - 截取字符串,从左至右以0开始,从右至左从-1开始
列表 List
- 列表元素支持数字、字符串、列表(嵌套)
- 列表元素用
[],用,分割元素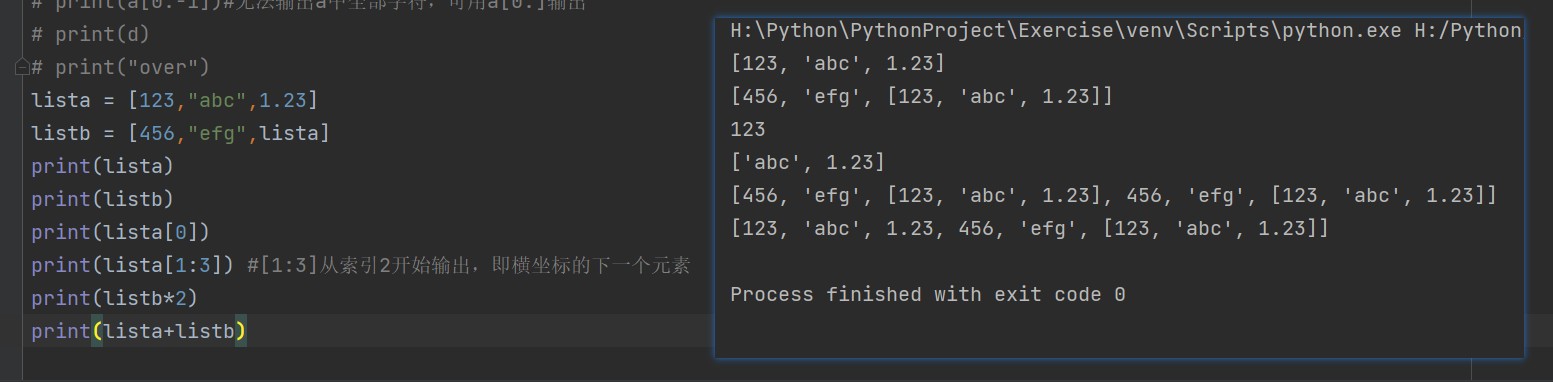
元组 Tuple
- Tuple与List类似,不同之处在于元组需要写在小括号
()里,元组的元素不能修改,并且元素之间要用逗号隔开 - String、List、Tuple都属于序列(Sequence),能够被索引和截取
集合 Set
- Set(集合)是一个无序的不重复元素序列,可以用大括号”{}“ 或者set()函数创建集合,创建一个空集必须用set()
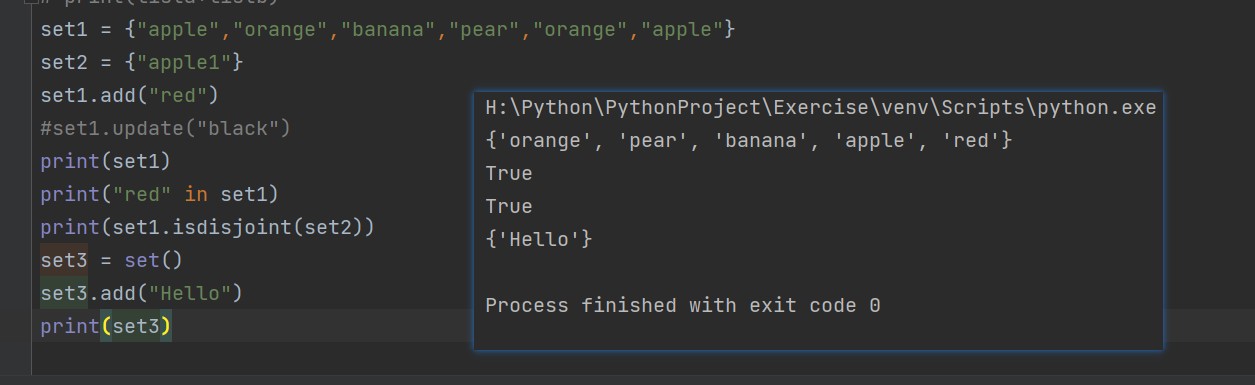
集合内置方法列表
add()为集合添加元素clear()移除集合中的所有元素copy()拷贝一个集合difference()返回多个集合的差集difference_update()移除集合中的元素,该元素在指定的集合也存在discard()删除集合中指定的元素intersection()返回集合的交集intersection_update()删除集合中的元素,,该元素在指定的集合中不存在isdisjoint()判断两个集合是否包含相同的元素,如果没有返回True,否则返回Falseissubset()判断指定集合是否为该方法参数集合的子集issuperset()判断该方法的参数集合是否为指定集合的子集pop()随机移除元素remove()移除指定元素symmetric_difference()返回两个集合中不重复的元素集合symmetric_difference_update()移除当前集合中与另外一个指定集合相同的元素,并另外一个指定集合中不同的元素插入到当前集合中union()返回两个集合的并集update()给集合添加元素
字典 Dictionary
- 列表是有序的对象集合,字典是无序的对象集合
- 字典中的元素是通过键来存取的
- 列表中的元素是通过存放顺序来读取的
- 字典是一种映射类型,用
{}标识,无序的键(key):值(value)的集合,key使用不可变类型,在同一个字典中,key必须是唯一的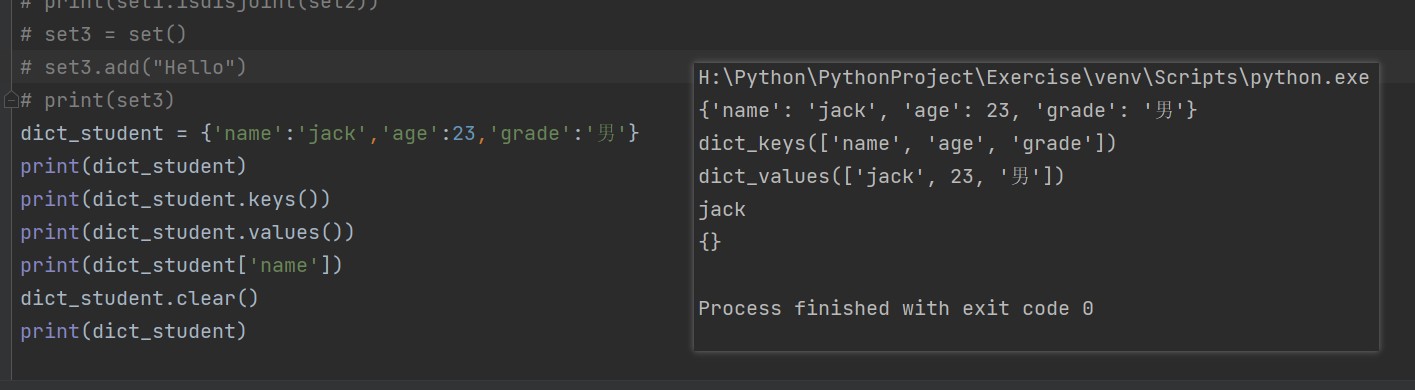
数据类型转换
数据类型的转换,只需要将数据类型作为函数名即可,可以执行数据类型之间转换的内置函数有15种。
int(x[,base])将x转换成整数float(x)将x转换成浮点数complex(real[,imag])创建一个复数str(x)将对象x转换成字符串repr(x)将对象x转换成表达式字符串eval(str)用来计算在字符串中的有效Python表达式,并返回一个对象tuple(s)将序列s转换成一个元组list(s)将序列s转换成一个列表set(s)转换成可变集合dict(d)创建一个字典,d必须是一个序列(key,value)元组frozenset(s)转换成不可变集合chr(x)将一个整数转换成一个字符ord(x)将一个字符转换成它的整数值hex(x)将一个整数转换成一个十六进制字符串oct(x)将一个整数转换成八进制字符串
运算符与表达式
- 算术运算符>关系运算符>逻辑运算符
算术运算符
+、-、*、/、%**幂:返回x的y次幂//取整除:向下取接近除数的整数关系运算符
==、!=、>、>、>=、<=逻辑运算符
and、or、not位运算符
&(与)、|(或)、^(异或)、~(取反)、<<(左移)、>>(右移)成员运算符
in在指定序列中找到返回True,not in同理身份运算符(比较两个对象的存储单元)
is判断两个标识符是不是引用自同一个对象,is not同理
end关键字
- 关键字
end可以用于将结果输出到同一行,或者在输出的末尾添加不同的字符
案例:截取字符串abcd,输出形式如下: a b b c c c d d d d 思路: ①创建字符串"adcd" ②双重循环,遍历输出,外循环控制行数,两内循环控制输出空格和字符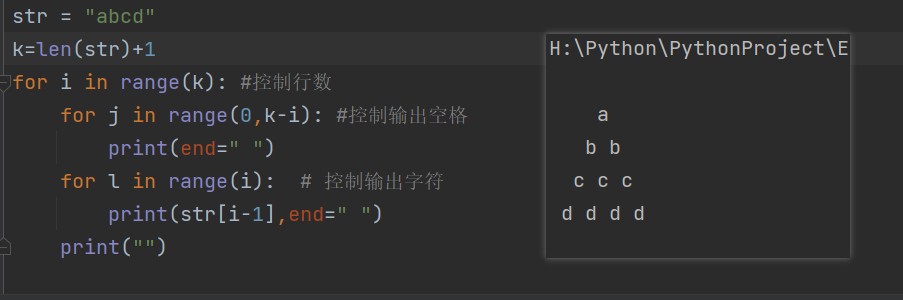
循环与判断
if/else 循环
- python的if语句格式
if condition1: statement_block_1 elif condition2: statement_block_2 else: statement_block_3
Python中用elif代替了else if,所以if关键字:if-elif-else
- python使用缩进来划分代码块,python没有
switch-case语句
if嵌套
- 嵌套格式
if 表达式1: 语句 if 表达式2: 语句 elif 表达式3: 语句 else: 语句 elif 表达式4: 语句 else: 语句
for循环
for循环可以遍历任何可迭代对象,如一个列表或者一个字符串
一般格式如下:for <variable> in <sequence>: <statements> if condition == "ok": break #当条件位ok时,跳出循环 else: <statements>
while循环
一般格式
while 判断条件(condition):
执行语句(statement)...python没有do_while循环
- while循环使用else
while <expr>: <statement(s)> else: <additional_statement(s)>
range()函数
- 当需要遍历数字序列,使用内置
range()函数,它会生成数列
结果:for i in range(5): print(i)
0
1
2
3
4range指定区间值range(5,9)#遍历5,6,7,8指定数字开始并指定不同的增量(步长)
range(0,100,20)#遍历0,20,40,60,80range()和len()函数以遍历一个序列的索引for i in range(len(L))range()函数创建一个列表list(range(5))
break和continue
break跳出循环体,并不执行循环体continue跳出当前循环,执行下一次循环
pass语句
python的pass是空语句,是为了保持程序结构的完整性,
pass不做任何事,一般用做占位语句。
while True:
pass迭代器与生成器
迭代器
迭代是python最强大的功能之一,是访问集合元素的一种方式
迭代器是一个可以记住遍历的位置的对象
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束,迭代器只能往前不会后退
迭代器有两个基本的方法:
iter()和next()字符串,列表或元组对象都可用于创建迭代器
创建迭代器对象
list = [1,2,3,4] it = iter(list) #创建迭代对象 print(next(it)) #输出迭代器中下一个元素for循环遍历迭代器list = [1,2,3,4] it = iter(list) for x in it: print(x,end=" ")next()函数遍历迭代器import sys #引入sys模块 list = [1,2,3,4] it = iter(list) while True: try: print(next(it)) except StopIteration: sys.exit()
创建一个迭代器
把一个类作为一个迭代器使用,就需要在类中实现两个方法_iter_()与_next_(),运用面向对象编程,就需要建立构造函数_init_(),初始化对象时使用。_iter_()方法返回一个特殊的迭代器对象,这个迭代器对象实现了_next_()方法并通过StopIteration异常标识迭代的完成。_next_()方法(python2里是next())会返回下一个迭代器对象
创建一个返回数字的迭代器,初始值为1,逐步递增1:class MyIter: # 创建类 def _iter_(self) #构建方法 self.a =1 return self def _next_(self): if self.a <= 20: #20次迭代后,StopIteration控制停止执行 x = self.a self.a += 1 return x else: raise StopIteration myiter = MyIter() #引用类 myiter1 = iter(myiter) print(next(myiter1)) print(next(myiter1))
- 生成器
在Python中,使用了yield的函数被称为生成器(generator)。与普通函数不同的是:生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点生成器就是一个迭代器。在调用生成器运行的过程中,每次运行yield时函数会暂停并保存当前所有的运行信息,返回yield的值,并在下一次执行next()方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。yield实现斐波那契数列
import sys def fibonacci(n): #生成器函数 a,b,counter = 0,1,0 while True: if(counter > n): return yield a a,b = b,a+b counter += 1 f = fibonacci(10) while True: try: print(next(f),end="") except StopIteration: sys.exit()
zip()并行迭代
- 使用
zip()函数可以对多个序列进行并行迭代,在最短序列”用完”时就会停止。names = ("zhang","wang","li") ages = (24,14,47,45) jobs = ("play","work") for name,age,job in zip(names,ages,jobs): print("{0}--{1}--{2}".format(name,age,job)) for i in range(min(names,ages,jobs)): #min(names,ages,jobs)伪代码,求数组最小长度 print("{0}--{1}--{2}".format(names[i],ages[i],job[i]))
输出:zhang--24--play
wang--14--work
推导式
列表推导式
列表推导式生成列表对象,语法如下:[表达式 for item in 可迭代对象]
或者:{表达式 for item in 可迭代对象 if 条件判断}
y = [x*2 for x in range(1,10)]
print(y)
y=[]
for i in range(1,10):
y.append(i*2)
print(y)
a = [a for a in "abcdefg"]
print(a)
cells = [(row,col) for row in range(1,10) for col in range(1,10)] #两次循环
for i in cells:
print(i)输出:[2, 4, 6, 8, 10, 12, 14, 16, 18]
[2, 4, 6, 8, 10, 12, 14, 16, 18]
['a', 'b', 'c', 'd', 'e', 'f', 'g']
(1, 1)
(1, 2)
(1, 3)
(1, 4)
(1, 5)
(1, 6)
(1, 7)
(1, 8)
(1, 9)
(2, 1)···
字典推导式
字典的推导式生成字典对象,格式如下:{key_expression : value_expression for 表达式 in 可迭代对象}
类似列表推导式,字典推导式也可以增加if条件判断,多个for循环
统计文本中字符出现的次数:
my_text = 'i love you,i love listening,i love game'
char_count = {c:my_text.count(c) for c in my_text}
print(char_count)输出:{'i': 5, ' ': 6, 'l': 4, 'o': 4, 'v': 3, 'e': 5, 'y': 1, 'u': 1, ',': 2, 's': 1, 't': 1, 'n': 2, 'g': 2, 'a': 1, 'm': 1}
集合推导式
集合推导式生成集合,和列表推导式的语法格式类似:{表达式 for item in 可迭代对象}
或者{表达式 for item in 可迭代对象 if 条件判断}
a = {x for x in range(1,100) if x%10 == 0}
print(a)输出{70, 40, 10, 80, 50, 20, 90, 60, 30}
生成器推导式(生成元组)
元组没有生成器原因:
a = (x for x in range(1,100) if x%9 == 0)
print(a)输出: <generator object <genexpr> at 0x0000028ED79BE900>返回一个生成器对象
生成器推导式:
gen = (x for x in range(1,100) if x%9 == 0)
for x in gen:
print(x,end = " ")
for x in gen:
print(x,end = " ")输出:9 18 27 36 45 54 63 72 81 90 99
- 可以看出迭代器第一次遍历可以得到数据,第二次数据就没有了
循环代码优化技巧
- 尽量减少循环内部不必要的计算
- 循环嵌套中,尽量减少内层循环的计算,尽可能向外提
- 局部变量查询较快,尽量使用局部变量
- 连接多个字符串,使用
join()而不使用+ - 列表进行元素查插入和删除,尽量在列表尾部操作
小练习
绘制5个同心圆
#绘制5个同心圆
import turtle
t = turtle.Pen()
t.hideturtle() # 隐藏最终的箭头
my_color = ("red","yellow","black","green")
t.width(4) #画笔宽度
t.speed(0) #画笔速度,0最快
for i in range(5):
t.penup() #抬笔
t.goto(0, -10*i)
t.pendown() #下笔
t.pencolor(my_color[i%len(my_color)]) #改变画笔颜色
t.circle(20+10*i)
turtle.done() #程序执行完,窗口不消失
绘制10x10方格
#绘制10*10方格
import turtle
t = turtle.Pen()
t.hideturtle() # 隐藏最终的箭头
t.speed(0)
for i in range(11):
t.penup()
t.goto(-200, 300-40*i)
t.pendown()
t.goto(200, 300-40*i)
t.penup()
t.goto(-200+40*i,300 )
t.pendown()
t.goto(-200+40*i, -100)
turtle.done()

函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段,函数可以提高应用的模块性和代码的重复使用率。
函数语法(默认情况下,参数值和参数名称是按函数声明中定义的顺序匹配)
def 函数名(参数列表): "'文档字符串'" #函数说明 函数体
文档字符串(函数的注释)
- 通过三个单引号或者三个双引号来实现,中间可以加入多行文字进行说明
def my1(): """文档字符串说明""" print("说明文档") def my2(): "'文档字符串说明'" my1() my2() - 使用help(函数名.doc)可以打印输出函数的文档字符串内容
help(my1.__doc__)
help(my2.__doc__)
- 输出:
No Python documentation found for '文档字符串说明1'. Use help() to get the interactive help utility. Use help(str) for help on the str class. No Python documentation found for "'文档字符串说明2'". Use help() to get the interactive help utility. Use help(str) for help on the str class.
函数返回值
- 函数体中包含
return语句,则结束函数执行并返回值 - 如何函数
return无指明返回值,则结束函数 - 函数体中不包含
return语句,则返回None值 - 返回多个返回值,使用列表、元组、字典、集合将多个值”存起来“
普通函数
变量起作用的范围称为变量的作用域,不同作用域内同名变量之间互不影响。变量分为:全局变量、局部变量
- 全局变量
- 在函数和类定义之外声明的变量。作用域为定义的模块,从定义位置开始直到模块结束
- 全局变量降低了函数的通用性和可读性,应尽量避免全局变量的使用
- 全局变量一般做常量使用
- 函数内要改变全局变量的值,使用
global声明一下
- 函数内要改变全局变量的值,使用
- 局部变量
- 在函数体中(包含形式参数)声明的变量
- 局部变量的引用比全局变量快,优先考虑使用
- 如果局部变量和全局变量同名,则在函数内隐藏全局变量,只使用同名的局部变量
输出:a = 100 #全局变量 def func1(i,j): global a a = 50 print("{0},{1},{2}".format(a,i,j)) #局部变量 a,i,j return print(a) func1(3,4) print(a)100 50,3,4 50
- 如果局部变量和全局变量同名,则在函数内隐藏全局变量,只使用同名的局部变量
函数传参
- 函数的参数传递本质上就是:从实参到形参的赋值操作。
Python中一切皆对象,所有的赋值操作都是”引用的赋值“。所以,Python中参数的传递都是”引用传递“,不是“值传递”。 - 对“可变对象”进行“写操作”,直接作用于原对象本身。
- 对“不可变对象”进行“写操作”,会产生一个新的“对象空间”,并用新的值填充这块空间。
- 可变对象:字典、列表、集合、自定义的对象等
- 不可变对象:数字、字符串、元组、function等
#传递可变对象
a = [10,20,30]
def func(i):
print(i)
i.append(40)
print(i)
func(a)
print(a)
#传递不可变对象
b = 100
def func1(i):
print(i)
i = i+10
print(i)
func1(b)
print(b)输出:[10, 20, 30]
[10, 20, 30, 40]
[10, 20, 30, 40]
100
110
100
浅拷贝和深拷贝
内置函数:copy浅拷贝、deepcopy深拷贝
- 浅拷贝:不拷贝子对象的内容,只是拷贝子对象的引用
- 深拷贝:会连子对象的内存也全部拷贝一份,对子对象的修改不会影响源对象
输出:#浅拷贝 import copy a = [10,[20,2],30] b = copy.copy(a) b.append([40,50]) b[1].append(60) print(a) print(b)[10, [20, 2, 60], 30] [10, [20, 2, 60], 30, [40, 50]]
#深拷贝
import copy
a = [10,20,[30,40],[50,60]]
b = copy.deepcopy(a)
b.append(20)
b[2].append(50)
print(b)输出:[10, 20, [30, 40, 50], [50, 60], 20]
浅拷贝只拷贝父类成员,而深拷贝拷贝父类和子类成员



