深度学习

- 层次化的概念让计算机构建较简单的概念来学习复杂概念。如果绘制出表示这些概念如何建立在彼此之上的一幅图,我们将得到一张“深”(层次很多)的图。由此,我们称这种方法为AI深度学习(deep learning)。
数学符号







第一章 引言
1.1 本书面向的读者
1.2 深度学习的历史趋势
- 深度学习的三架马车:算力、数据、算法
1.2.1 神经网络的众多名称和命运变迁
1.2.2 与日俱增的数据量
1.2.3 与日俱增的模型规模
1.2.4 与日俱增的精度、复杂度和对现实世界的冲击
参考资料


第一部分 应用数学与机器学习基础
第二章 线性代数
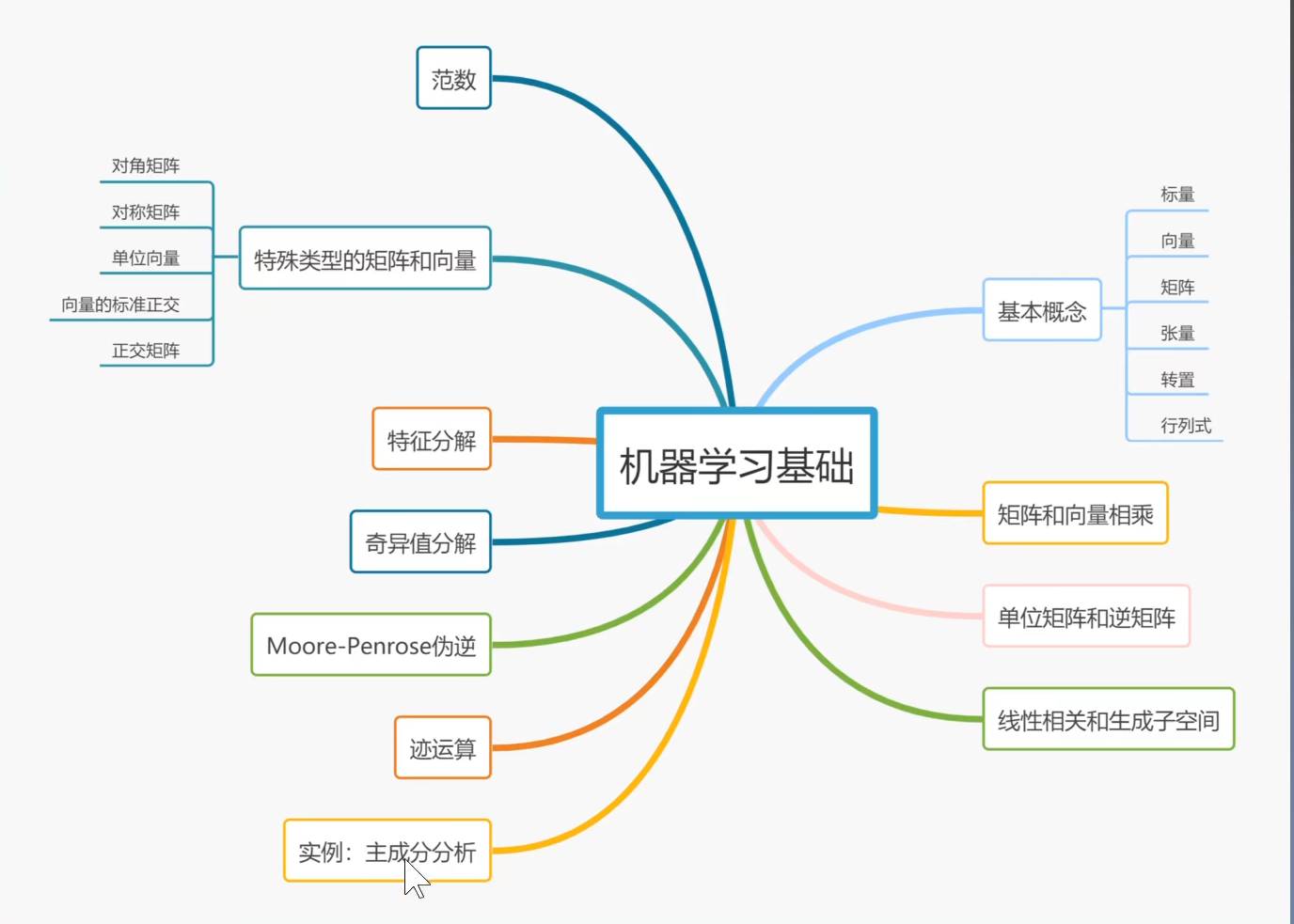
2.1 标量、向量、矩阵和张量
- 标量:一个数
- 向量:一行数或一列数
- 矩阵:二维数组
- 张量:多个矩阵
- 转置:作用于矩阵,行变列,列变行

2.2 矩阵和向量相乘

- 向量和矩阵相乘,向量需满足矩阵的行数
- 标量和矩阵相乘,即标量乘以矩阵的每一个元素
2.3 单位矩阵和逆矩阵
- 单位矩阵:主对角线为1,其他为0的矩阵
- 逆矩阵:矩阵乘以逆矩阵等于单位矩阵

2.4 线性相关和生成子空间



2.5 范数



2.6 特殊类型的矩阵和向量


2.7 特征分解



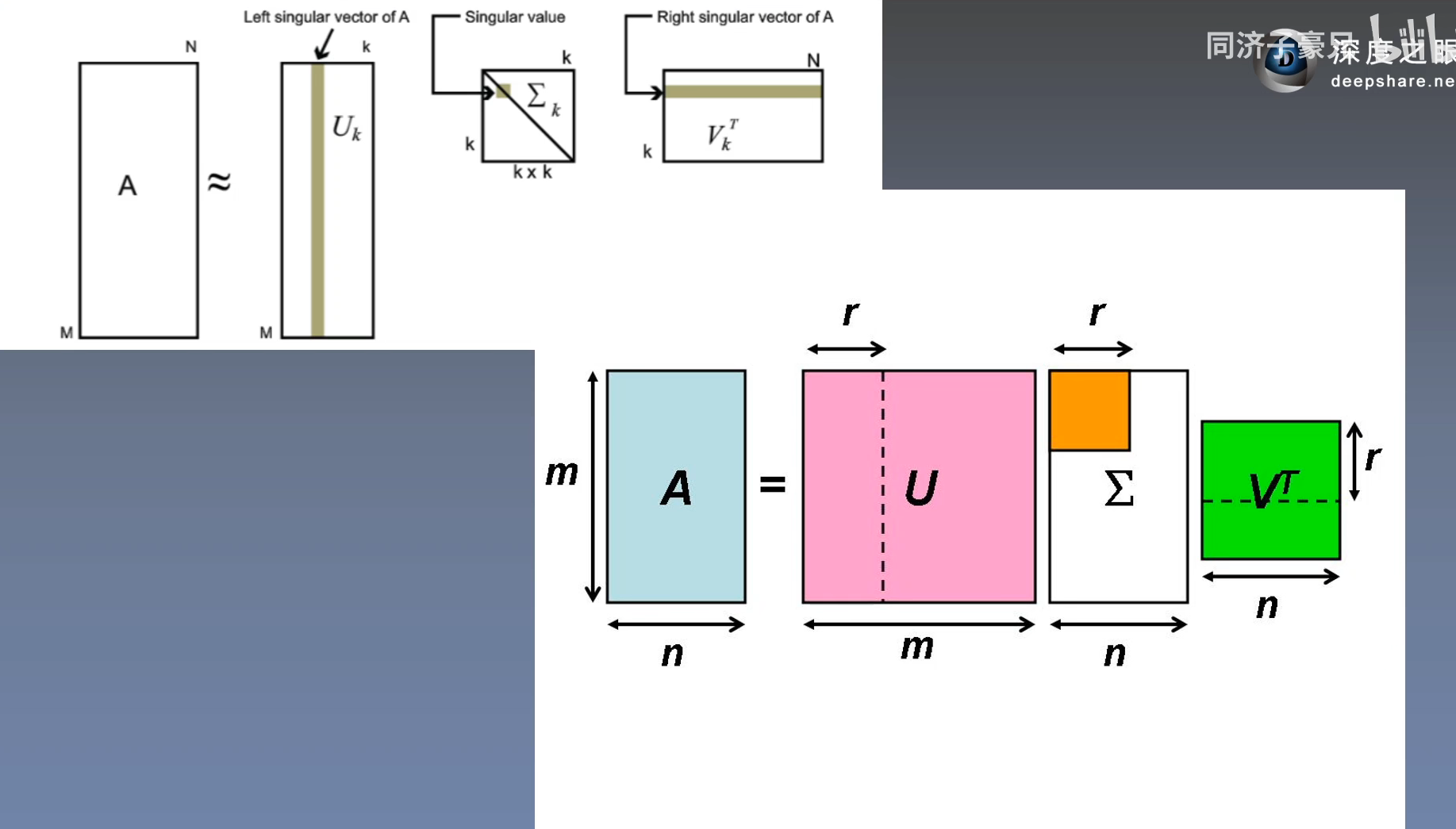
2.8 奇异值分解


2.9 Moore-Penrose伪逆


2.10 迹运算


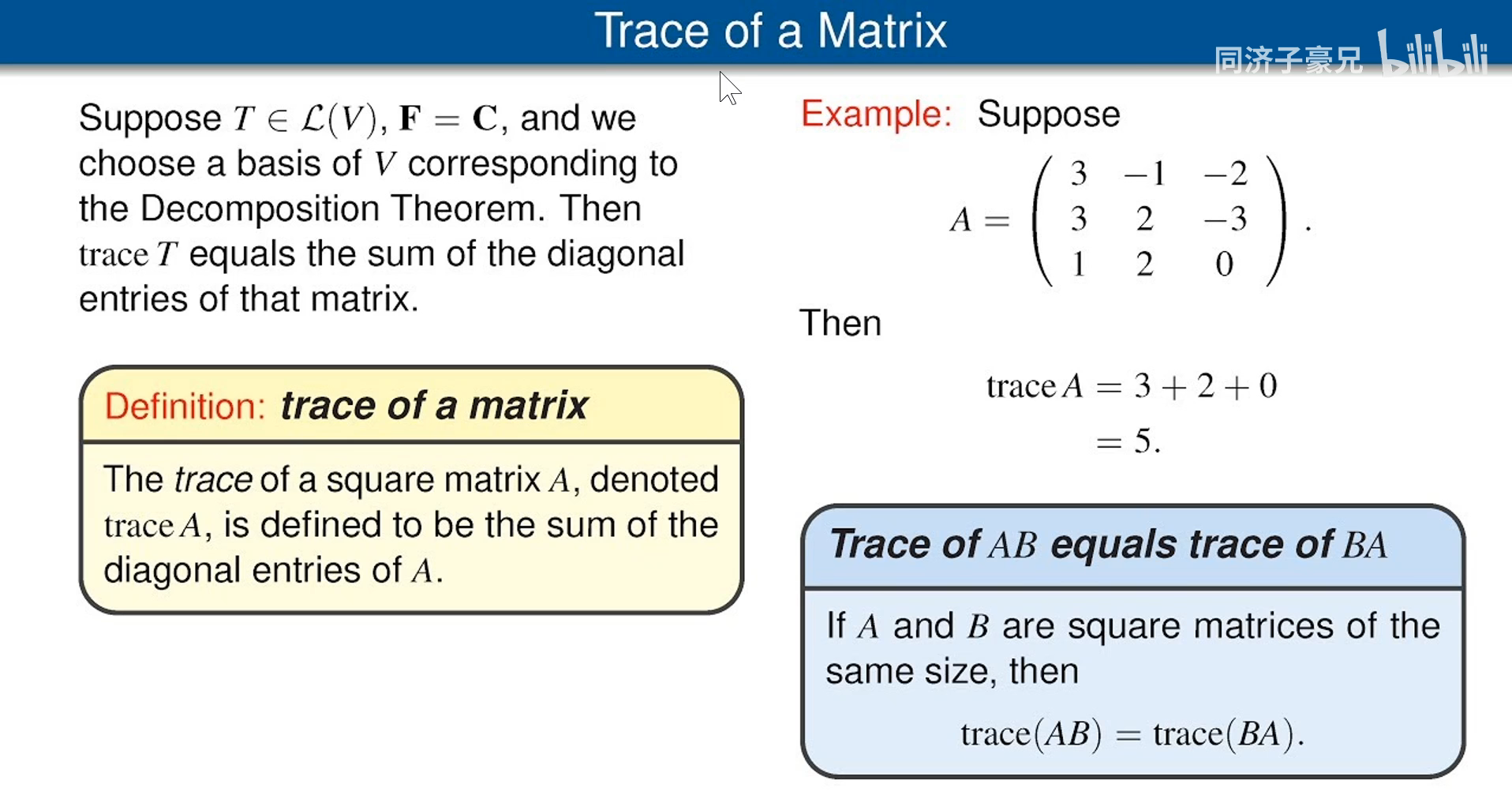
2.11 行列式

2.12 实例:主成分分析






- PCA降维算法



第三章 概率与信息论
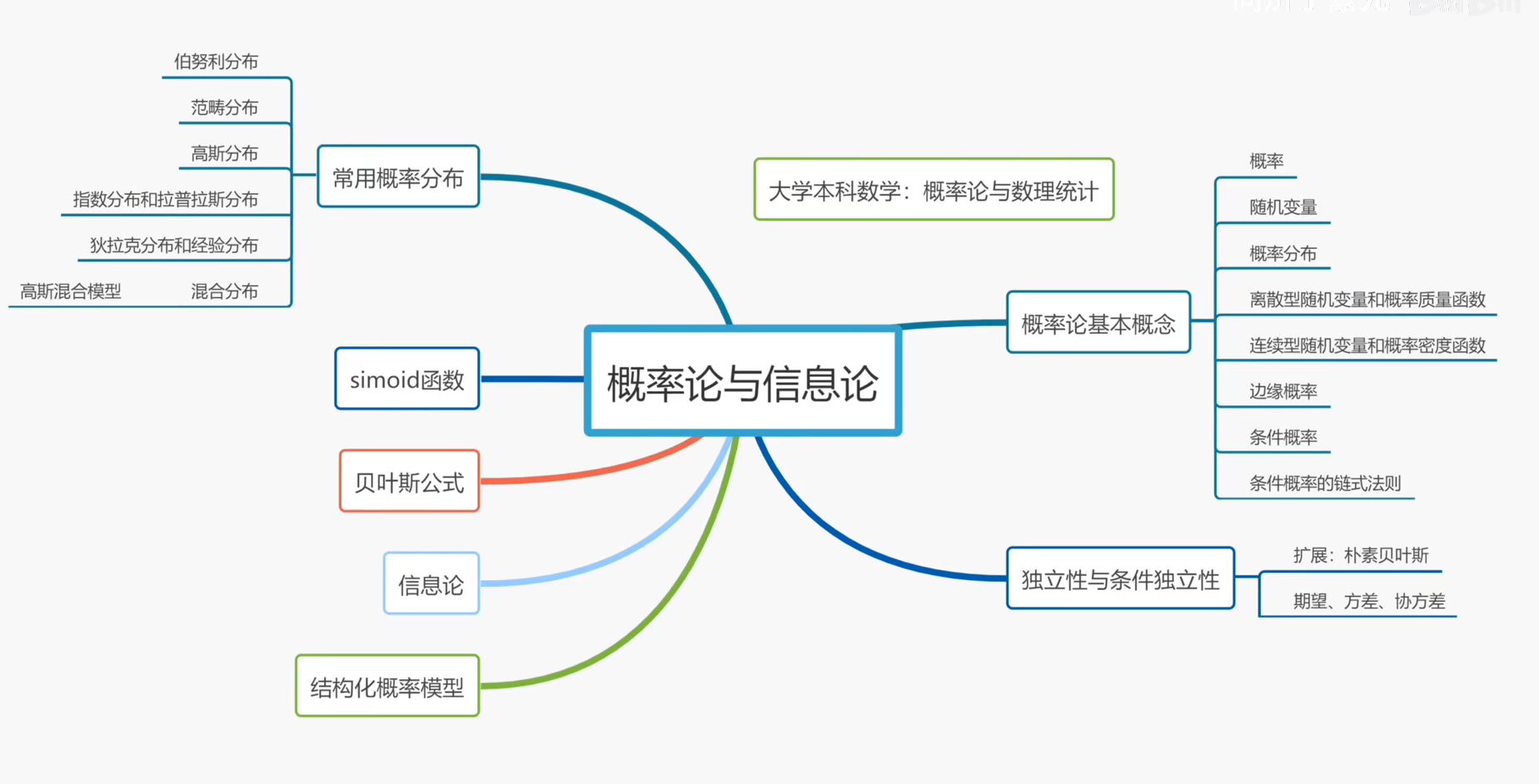
3.1 为什么用使用概率
3.2 随机变量
3.3 概率分布

3.3.1 离散型变量和概率质量函数
3.3.2 连续型变量和概率密度函数
3.4 边缘概率
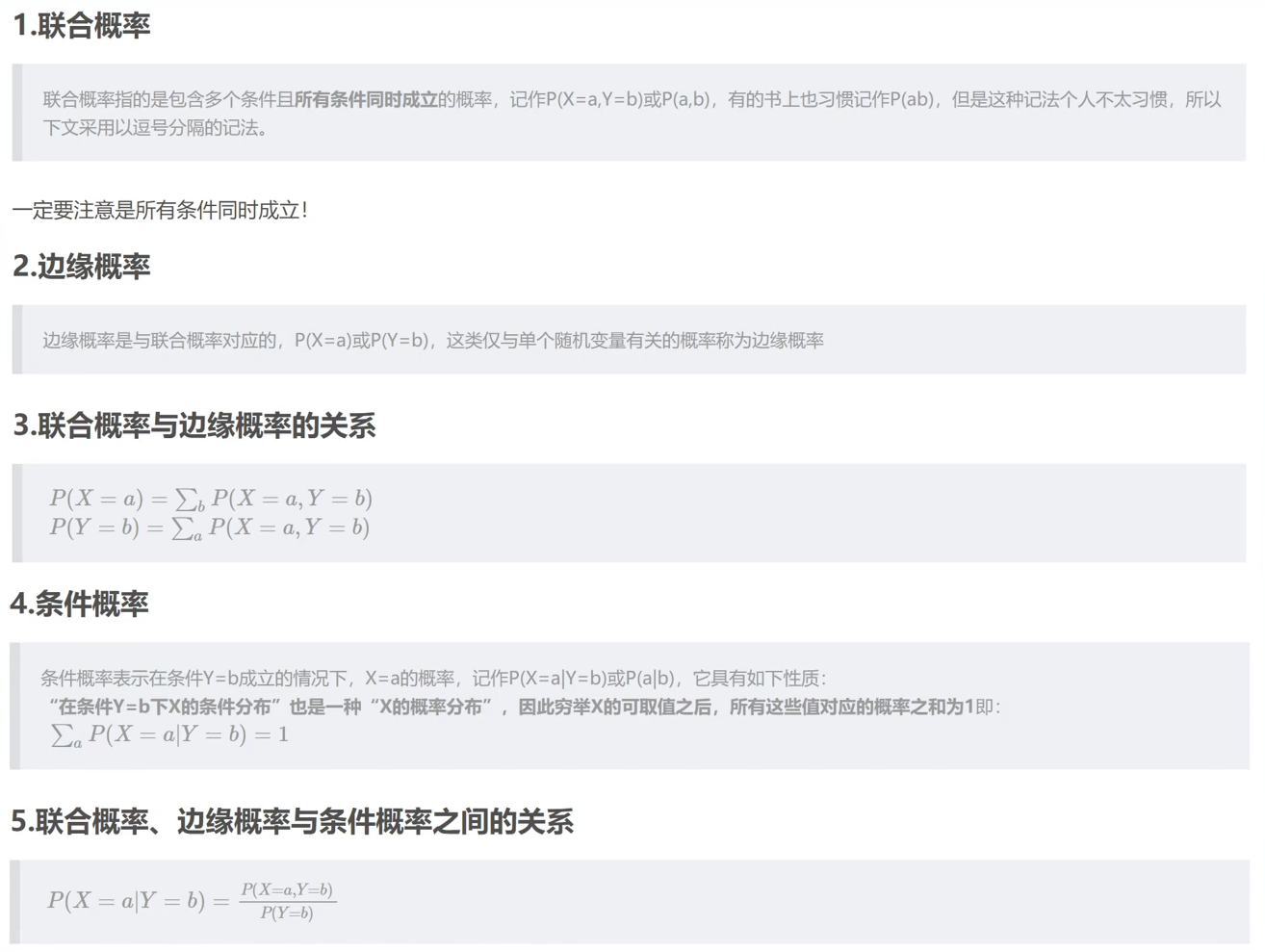
3.5 条件概率
3.6 条件概率的链式法则
3.7 独立性和条件独立性
3.8 期望、方差和协方差
3.9 常用概率分布
3.9.1 Bernoulli分布
3.9.2 Multinoulli分布
3.9.3 高斯分布
3.9.4 指数分布和Laplace分布
3.9.5 Dirac分布和经验分布
3.9.6分布的混合
3.10 常用函数的有用性质
3.11 贝叶斯规则


3.12 连续型变量的技术细节
3.13 信息论
3.14 结构化概率模型
第四章 数值计算

4.1 上溢和下溢
4.2 病态条件
4.3 基于梯度的优化方法

4.3.1 梯度之上:Jacobian和Hessian矩阵
4.4 约束优化
4.5 实例:线性最小二乘
第五章 机器学习基础


- 数值分析库SciPy




5.1 学习算法
5.1.1 任务T
5.1.2 性能度量P
5.1.3 经验E
5.1.4 示例:线性回归
5.2 容量、过拟合和欠拟合
5.2.1 没有免费午餐定理
5.2.2 正则化
5.3 超参数和验证集
5.3.1 交叉验证
5.4 估计、偏差和方差
5.4.1 点估计
5.4.2 偏差
5.4.3 方差和标准差
5.4.4 权衡偏差和方差以最小化均方误差
5.4.5 一致性
5.5 最大似然估计

5.5.1 条件对数似然和均方误差
5.5.2 最大似然的性质
5.6 贝叶斯估计
5.6.1 最大后验(MAP)估计
5.7 监督学习算法
5.7.1 概率监督学习
5.7.2 支持向量机
5.7.3 其他简单的监督学习算法
5.8 无监督学习算法
5.8.1 主成分分析
5.8.2 k-均值聚类
5.9 随机梯度下降
5.10 构建机器学习算法
5.11 促使深度学习发展的挑战
5.11.1 维数灾难
5.11.2 局部不变性和平滑正则化
5.11.3 流形学习
第二部分 深度网络:现代实践
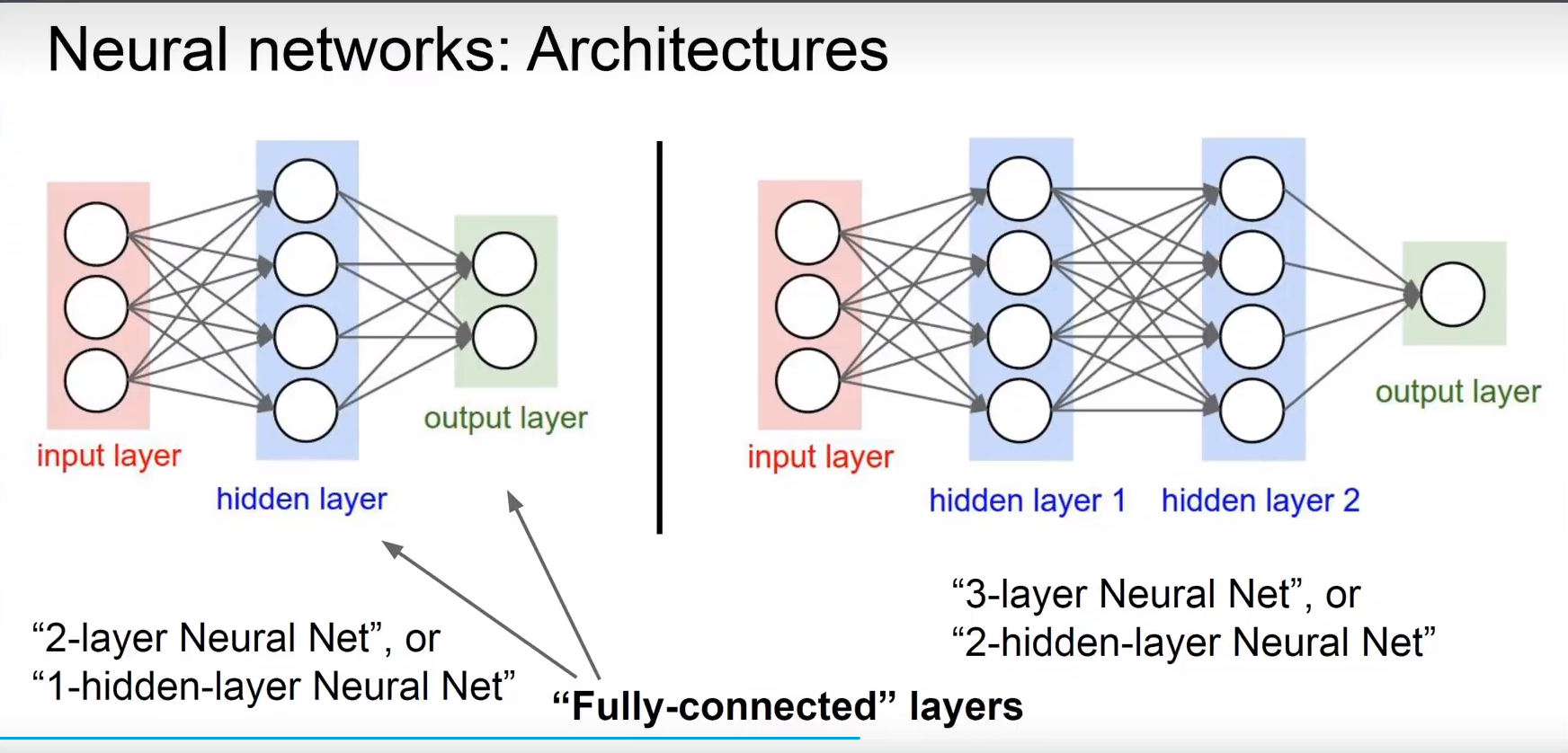
第六章 深度前馈网络









6.1 实践:学习XOR
6.2 基于梯度的学习
6.2.1 代价函数
6.2.2 输出单元
6.3 隐藏单元
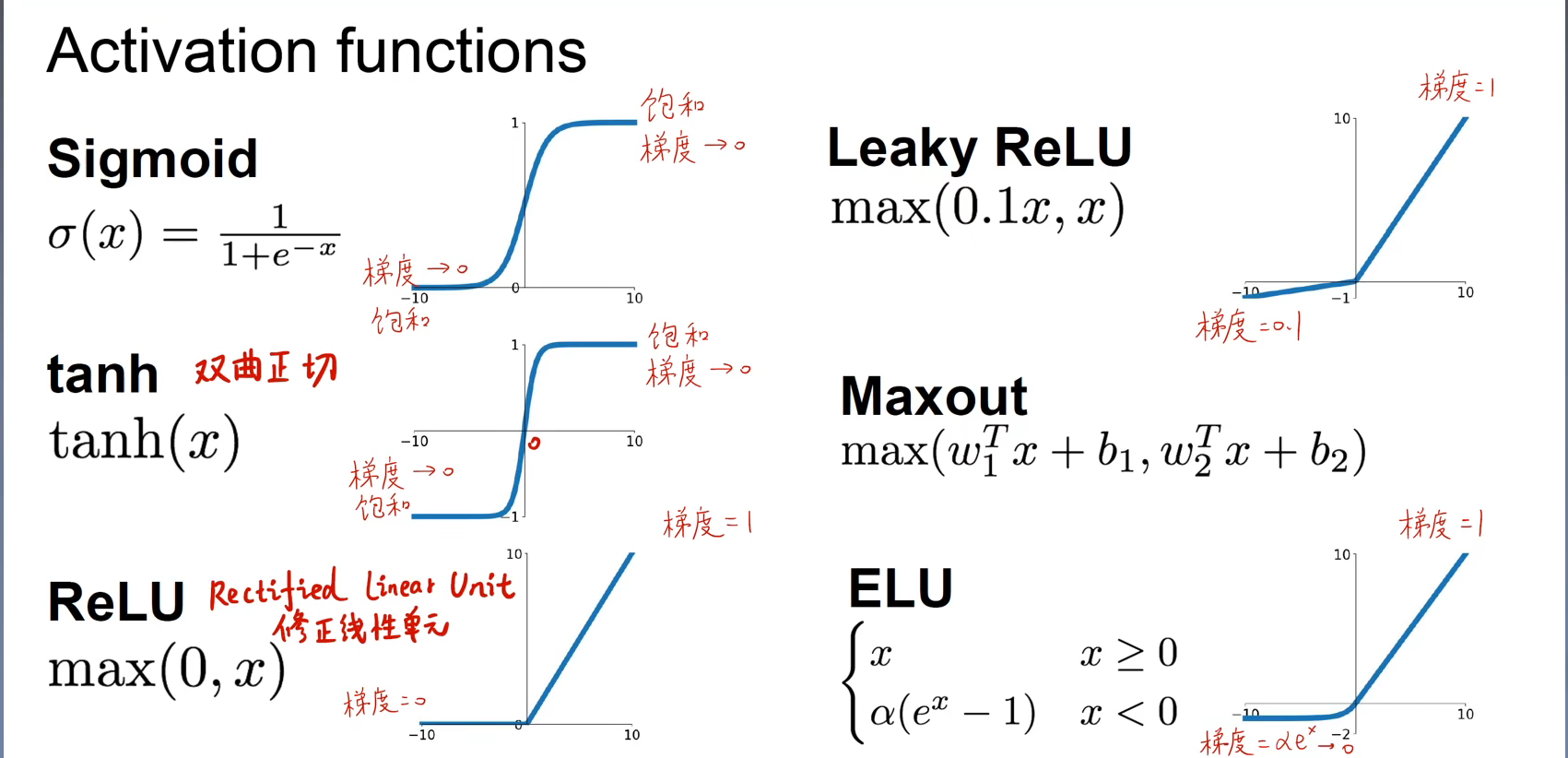
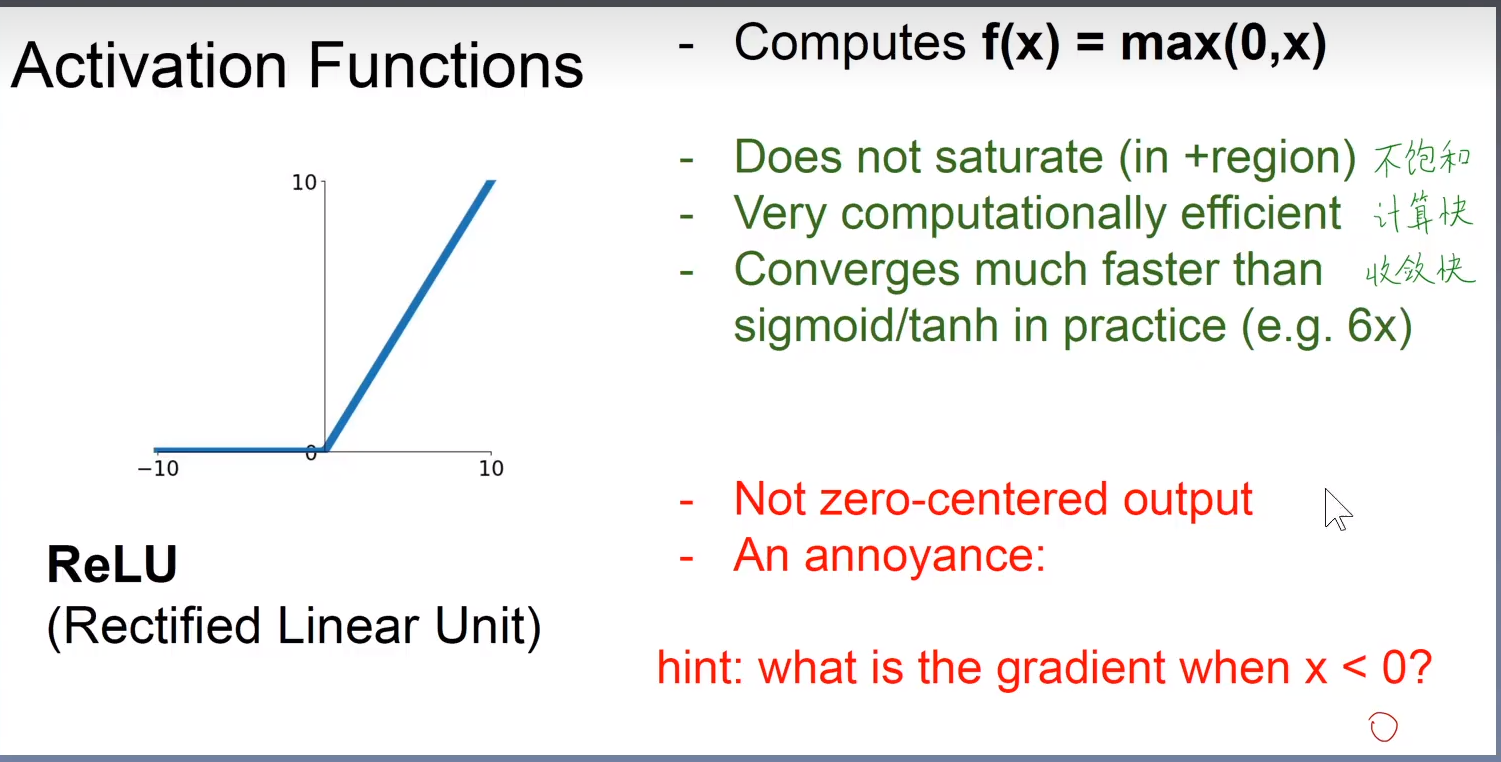
6.3.1 整流线性单元及其扩展
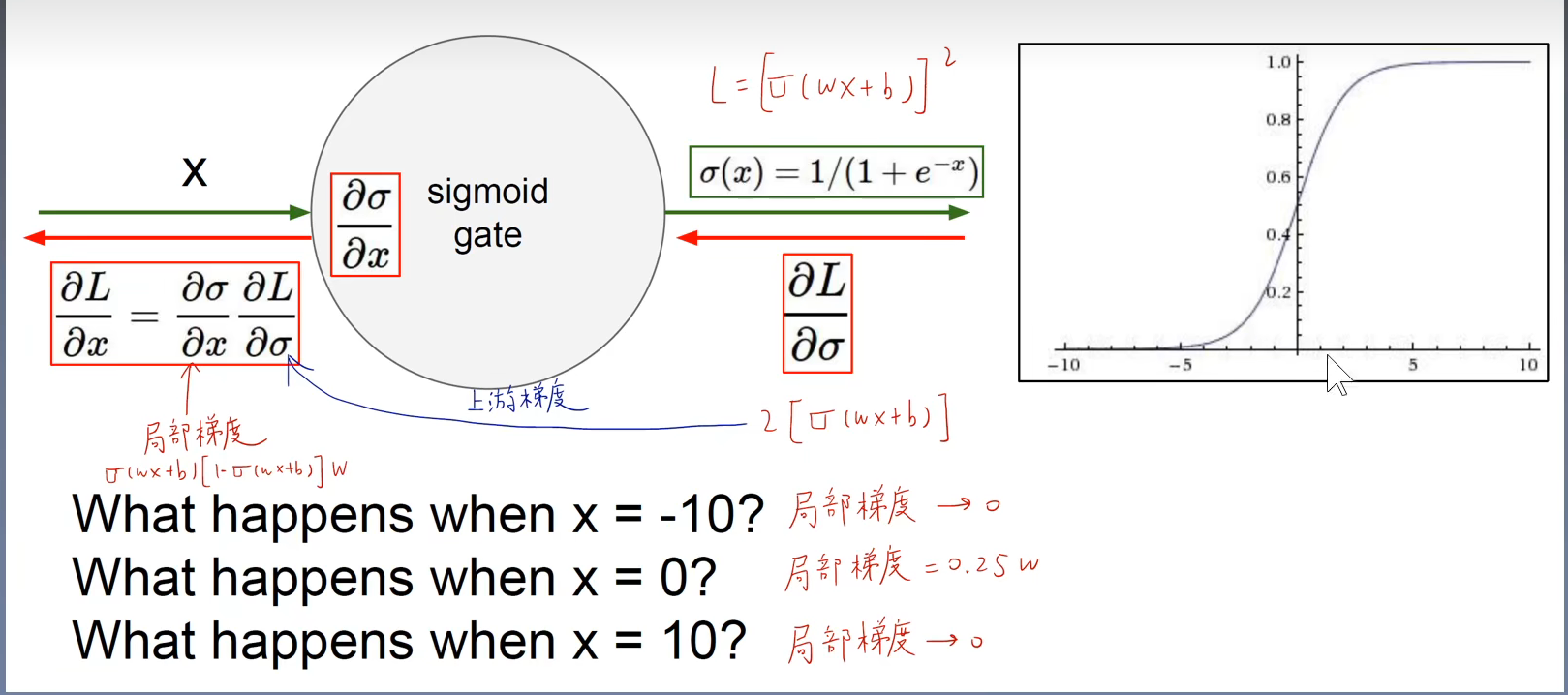
6.3.2 logistic sigmoid与双曲正切函数
6.3.3 其他隐藏单元
6.4 架构单元
6.4.1 万能近似性质和深度
6.4.2 其他架构上的考虑
6.5 反向传播和其他的微分算法