工业生产线 AI 监控系统
- 目标:生产线实时监控 + 图形化界面 + AI 分析反馈决策
一、整体架构设计
采用工业物联网标准四层架构:
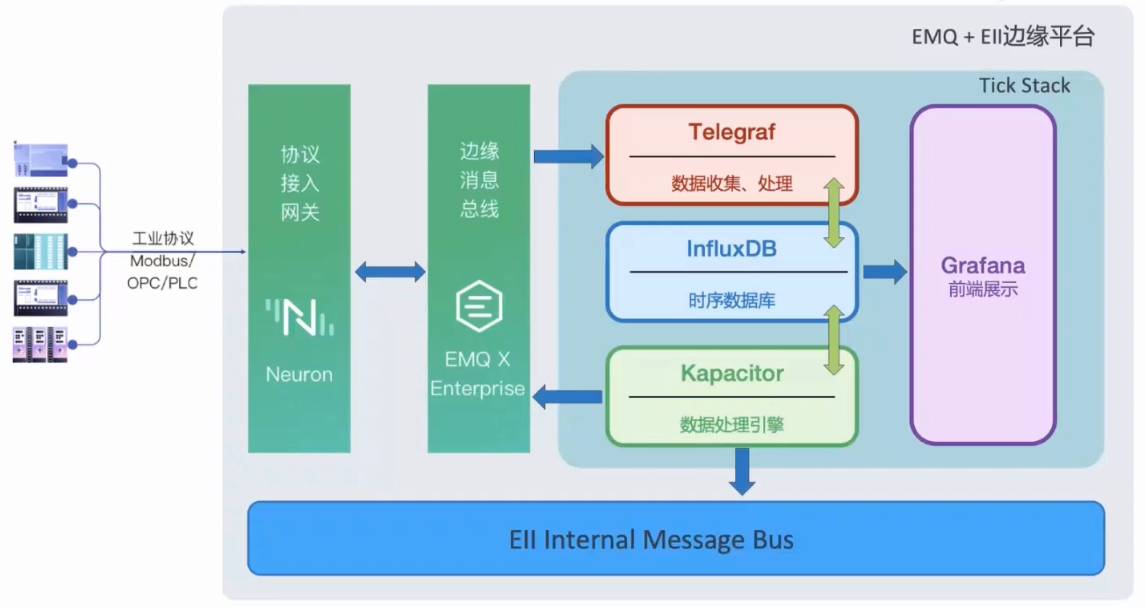
【PLC生产线】 ←Modbus TCP→ 【Neuron】 ←MQTT→ 【消息/数据库】 ←→ 【可视化大屏】 ←→ 【Ollama大模型】←→ 【分析决策】←→ 【预测性维护】四层详细说明
- 设备层
- PLC、传感器、执行器、生产线设备
- 通信协议:Modbus TCP
- 采集层(你已用 Neuron)
- Neuron 作为工业协议网关
- 负责:采集 PLC 数据、点位映射、协议转换(转 MQTT)
- 平台层(服务器)
- 消息中间件:MQTT Broker(EMQX 最推荐)
- 时序数据库:InfluxDB / TDengine(存工业历史数据)
- 服务接口:FastAPI/NodeJS(对接 Ollama 大模型)
- 应用层(核心交付)
- 图形化监控大屏(Web 网页,可全屏、可投屏)
- AI 分析决策、告警、报表、设备诊断、预测性维护
二、核心功能设计思路
1. Neuron 配置思路
Neuron 是整个系统的数据入口,配置目标:
- 添加 Modbus TCP 南向驱动,连接 PLC
- 配置 PLC 的 IP、端口、寄存器地址(保持与程序一致)
- 开启 MQTT 北向应用,把数据推送到服务器 MQTT
- 配置点位:温度、压力、转速、电流、产量、状态、报警等
最终效果:Neuron 自动把 PLC 数据实时上传到云端 / 服务器,无需写代码。
2. 数据流转设计(最关键)
PLC → Neuron(采集) → MQTT(传输) → 数据库(存储) → 可视化(展示) + AI(分析)- 实时性:100ms~500ms 刷新一次
- 可靠性:断网续传、数据不丢失
- 标准化:所有数据统一格式,方便 AI 读取
3. 图形化界面(Web 监控大屏)设计思路
使用 Grafana(工业最常用、零代码、最强可视化)
也可以用 DT Cloud / 自研 Vue 网页,但 Grafana 最快落地。
界面必须包含模块:
- 生产线总览(设备运行状态、整体流程图)
- 实时数据面板(温度、压力、电流、转速等数字仪表)
- 趋势曲线图(24 小时 / 7 天历史趋势)
- 告警面板(异常自动变红、弹窗、声音提示)
- 产量统计(当日产量、合格率、运行时长)
- AI 分析结果(大模型给出的诊断、建议)
4. Ollama 大模型接入思路(工业 AI 核心)
大模型不直接连 PLC,而是读取服务器的历史 / 实时数据做分析:
- 异常诊断:数据异常 → 大模型分析原因
- 预测性维护:根据历史趋势 → 预测设备可能故障时间
- 自然语言问答:员工用文字提问 → 大模型回答生产线状态
- 报表生成:自动生成生产日报、周报
接入方式:
- 写一个简单 Python 服务,定时从数据库读取数据
- 调用 Ollama 本地大模型接口
- 将 AI 分析结果写回数据库,展示在大屏上
三、技术栈清单(全部开源免费、可商用)
| 层级 | 工具 / 软件 | 作用 |
|---|---|---|
| 设备 | PLC | 生产线控制 |
| 采集 | Neuron | Modbus TCP 数据采集 |
| 消息 | EMQX | MQTT 消息转发 |
| 存储 | InfluxDB | 工业时序数据存储 |
| 可视化 | Grafana | 图形化监控大屏 |
| AI | Ollama + 本地大模型 | 数据分析、问答、诊断 |
| 接口 | Python FastAPI | 对接大模型 |
四、部署实施步骤
Neuron 连接 PLC
安装 MQTT 服务器(EMQX)
配置 Neuron 北向 MQTT(数据往外发)
需要先在服务器装 EMQX(免费 MQTT Broker)
安装 EMQX(Linux/Windows 都可)
- Windows:直接解压绿色版,双击启动
- Linux 一键安装:
curl -s https://packagecloud.io/install/repositories/emqx/emqx/script.deb.sh | sudo bash sudo apt install emqx sudo systemctl start emqx默认访问:
http://服务器IP:18083MQTT 端口:
1883Neuron 配置北向 MQTT
左侧【应用管理】→【添加应用】
应用类型:MQTT
名称:本地 MQTT 服务器
连接参数:MQTT 地址:
tcp://服务器IP:1883客户端 ID:自定义不重复
主题前缀:
/plc/prod/line1上报格式:JSON
保存并启用。
✅ 效果:
Neuron 每 200ms 把 PLC 所有点位数据,以 JSON 格式推送到 MQTT。
Neuron 配置 MQTT 上传
安装时序数据库(InfluxDB)
一、安装 InfluxDB(Ubuntu 一键版)
- 先加官方源
wget -qO- https://repos.influxdata.com/influxdata-archive.key | gpg --dearmor | sudo tee /usr/share/keyrings/influxdata-archive-keyring.gpg >/dev/null echo "deb [signed-by=/usr/share/keyrings/influxdata-archive-keyring.gpg] https://repos.influxdata.com/debian stable main" | sudo tee /etc/apt/sources.list.d/influxdata.list sudo apt update- 安装 InfluxDB 2.x(最新稳定版)
sudo apt install influxdb2 -y- 启动并设置开机自启
sudo systemctl start influxdb sudo systemctl enable influxdb sudo systemctl status influxdb看到
active (running)就是成功 ✅
二、初始化 InfluxDB(创建用户 / 桶 / 令牌)
打开浏览器访问:
http://你的服务器IP:8086点击 Get Started
设置:
- 用户名:
admin - 密码:自己设一个,比如
Influx@123 - 组织名:
factory - 桶名:
plc_data
- 用户名:
完成后,进入
Load Data → API Tokens,复制一个All Access令牌备用。
三、修改你的 Python 脚本,数据写入 InfluxDB
先安装依赖:
source myenv/bin/activate pip install influxdb-client替换成这个新脚本(自动写入 InfluxDB)
import json import time import paho.mqtt.client as mqtt from influxdb_client import InfluxDBClient, Point from influxdb_client.client.write_api import SYNCHRONOUS # ---------- 这里改成你自己的配置 ---------- MQTT_HOST = "192.168.10.100" MQTT_PORT = 1883 MQTT_USER = "root" MQTT_PASS = "root" MQTT_TOPIC = "/neuron/MQTT/attributes" INFLUX_URL = "http://localhost:8086" # 把下面这行换成你刚复制的 Token INFLUX_TOKEN = "ciKpzuEdkag4ZMwdeV_ApOhsuuk4lrS51X_a3x9j2zb_IzzN9ooaP1Rkz3YbqgCI2euTqIhAmWDoPU0o_nWQ4Q==" INFLUX_ORG = "factory" INFLUX_BUCKET = "plc_data" # ----------------------------------------- # 连接 InfluxDB client = InfluxDBClient(url=INFLUX_URL, token=INFLUX_TOKEN, org=INFLUX_ORG) write_api = client.write_api(write_options=SYNCHRONOUS) def on_connect(client, userdata, flags, rc, properties=None): print("✅ MQTT 连接成功") client.subscribe(MQTT_TOPIC) print("✅ 已订阅主题:" + MQTT_TOPIC) def on_message(client, userdata, msg): try: data = json.loads(msg.payload.decode()) ts = int(time.time() * 1000) temperature = float(data.get("温度", 0.0)) pressure = float(data.get("压力", 0.0)) run_status = int(data.get("运行状态", 0)) total = int(data.get("产量", 0)) point = Point("prod_data") \ .field("temperature", temperature) \ .field("pressure", pressure) \ .field("run_status", run_status) \ .field("total", total) \ .time(ts, write_precision='ms') write_api.write(bucket=INFLUX_BUCKET, org=INFLUX_ORG, record=point) print(f"✅ 写入成功 | 温度={temperature} 压力={pressure} 运行={run_status} 产量={total}") except Exception as e: print("❌ 错误:", e) # 启动 MQTT mqtt_client = mqtt.Client(mqtt.CallbackAPIVersion.VERSION2) mqtt_client.username_pw_set(MQTT_USER, MQTT_PASS) mqtt_client.on_connect = on_connect mqtt_client.on_message = on_message mqtt_client.connect(MQTT_HOST, MQTT_PORT, 60) mqtt_client.loop_forever()保存后运行:
python3 mqtt2td.py
四、Grafana 直接用 InfluxDB(自带支持)
左侧菜单 → Connections → Data sources → Add data source
搜索 InfluxDB,选中它
配置:
- URL:
http://127.0.0.1:8086 - 选择 InfluxDB 2.x
- Organization:
factory - Token: 你复制的 InfluxDB 令牌
- Default Bucket:
plc_data
- URL:
- 点 Save & Test,绿色对勾就是成功 ✅
安装 Grafana 并连接数据库
sudo apt install -y apt-transport-https software-properties-common wget wget -q -O - https://apt.grafana.com/gpg.key | sudo apt-key add - echo "deb https://apt.grafana.com stable main" | sudo tee /etc/apt/sources.list.d/grafana.list sudo apt update && sudo apt install grafana -y安装完立即启动 + 开机自启
sudo systemctl start grafana-server sudo systemctl enable grafana-server查看是否运行成功
sudo systemctl status grafana-server看到 active (running) 就是成功 ✅
现在你可以访问可视化大屏了!
打开浏览器访问:
默认登录账号密码:
用户名:admin
密码:admin
(第一次登录会让你改密码,直接点Skip跳过也行)
制作监控大屏
在 Grafana 里创建第一个监控面板
点击左侧菜单 Dashboards → New dashboard
点击 Add visualization
数据源选择你刚配置好的
influxdb在查询框里,粘贴下面的 Flux 语句:
from(bucket: "plc_data") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r._measurement == "prod_data") |> filter(fn: (r) => r._field == "temperature" or r._field == "pressure") |> yield(name: "实时数据")点击右上角的 Run query,就能看到温度和压力的实时曲线了!
扩展更多监控指标
你可以再添加几个面板,分别显示不同的数据:
运行状态(单值卡片)
from(bucket: "plc_data") |> range(start: -1m) |> filter(fn: (r) => r._measurement == "prod_data" and r._field == "run_status") |> last()设置成
Stat面板,用不同颜色区分运行 / 停止状态。产量统计(累计值)
from(bucket: "plc_data") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r._measurement == "prod_data" and r._field == "total") |> last()
最终效果
现在你的整套系统已经完全跑通了:
PLC → Neuron → EMQX → Python脚本 → InfluxDB → Grafana 可视化大屏你可以根据需要继续添加更多设备、更多点位的监控,或者设置数据告警。
部署 Ollama 接口服务
一键安装 Ollama(1 秒搞定)
直接在终端运行这 1 行命令:
curl -fsSL https://ollama.com/install.sh | sh安装完成后,服务会自动启动,不用手动开!
启动对外 API 接口(关键!)
Ollama 默认只允许本机访问,你要让 Grafana / 外部程序 / 网页 调用,必须开启对外接口:
创建 Ollama 系统服务配置
sudo nano /etc/systemd/system/ollama.service把下面内容完整粘贴进去
[Unit] Description=Ollama Service After=network.target [Service] Environment="OLLAMA_HOST=0.0.0.0" Environment="OLLAMA_PORT=11434" ExecStart=/usr/bin/ollama serve User=root Group=root Restart=always RestartSec=3 [Install] WantedBy=multi-user.target保存并重启服务
sudo systemctl daemon-reload sudo systemctl restart ollama sudo systemctl enable ollama
✅ 现在你的 Ollama 接口已经部署完成!
http://你的服务器IP:11434
测试接口是否可用
curl http://localhost:11434/api/tags如果返回 JSON 信息 = 接口服务运行成功!
你可以直接运行 AI 大模型(比如 Qwen 7B)
ollama run qwen:7b或者轻量版:
ollama run qwen:4b
对外 API 调用示例(给你备用)
curl http://192.168.10.100:11434/api/generate -d '{ "model": "qwen:7b", "prompt": "分析一下生产线温度数据是否正常" }'
AI 分析接入大屏
实现效果:
- 定时读取 PLC 实时数据(温度 / 压力 / 运行状态 / 产量)
- 调用本地 Ollama AI 做工况分析、异常判断、生产建议
- AI 分析结果存入 InfluxDB
- Grafana 大屏直接展示「AI 文字分析 + 数据曲线」
第一步:确认环境
Ollama 对外接口已开启
curl http://127.0.0.1:11434/api/tags提前拉一个轻量模型(推荐通义千问,速度快)
ollama pull qwen:3b
第二步:新建 AI 分析服务脚本
nano ai_analysis.py完整代码(直接复制)
import json import time import requests from influxdb_client import InfluxDBClient, Point from influxdb_client.client.query_api import QueryApi # ==================== 配置 ==================== # InfluxDB INFLUX_URL = "http://127.0.0.1:8086" INFLUX_TOKEN = "ciKpzuEdkag4ZMwdeV_ApOhsuuk4lrS51X_a3x9j2zb_IzzN9ooaP1Rkz3YbqgCI2euTqIhAmWDoPU0o_nWQ4Q==" INFLUX_ORG = "factory" INFLUX_BUCKET = "plc_data" # Ollama AI OLLAMA_API = "http://127.0.0.1:11434/api/generate" AI_MODEL = "qwen:3b" # =============================================== # 连接 InfluxDB db_client = InfluxDBClient(url=INFLUX_URL, token=INFLUX_TOKEN, org=INFLUX_ORG) write_api = db_client.write_api() query_api = db_client.query_api() # 读取最新PLC数据 def get_last_plc_data(): query = f''' from(bucket:"{INFLUX_BUCKET}") |> range(start: -5m) |> filter(fn: (r) => r._measurement == "prod_data") |> last() ''' tables = query_api.query(query) data = {} for table in tables: for record in table.records: data[record.get_field()] = record.get_value() return data # AI 分析 def ai_analyse(data): prompt = f""" 你是工业生产线运维AI分析师,根据以下实时工况数据,简短分析: 温度:{data.get("temperature",0)} ℃ 压力:{data.get("pressure",0)} MPa 设备运行状态:{data.get("run_status",0)} 今日产量:{data.get("total",0)} 要求: 1. 判断设备是否正常、有无异常 2. 给出简短运维建议 3. 控制在80字以内 """ payload = { "model": AI_MODEL, "prompt": prompt, "stream": False } res = requests.post(OLLAMA_API, json=payload, timeout=30) return res.json()["response"].strip() # 主循环 if __name__ == "__main__": print("✅ 工业AI分析服务已启动,每60秒自动分析一次") while True: try: plc_data = get_last_plc_data() if not plc_data: time.sleep(10) continue ai_text = ai_analyse(plc_data) print("🤖 AI分析结果:", ai_text) # AI结果写入InfluxDB,给Grafana展示 point = Point("ai_result")\ .field("analysis", ai_text)\ .time(time.time_ns()) write_api.write(bucket=INFLUX_BUCKET, org=INFLUX_ORG, record=point) except Exception as e: print("❌ 错误:", e) time.sleep(60) # 60秒分析一次保存:
Ctrl+O回车 →Ctrl+X
第三步:安装依赖
source myenv/bin/activate pip install requests influxdb-client
第四步:填入你的 InfluxDB Token
INFLUX_TOKEN = "ciKpzuEdkag4ZMwdeV_ApOhsuuk4lrS51X_a3x9j2zb_IzzN9ooaP1Rkz3YbqgCI2euTqIhAmWDoPU0o_nWQ4Q=="
第五步:启动 AI 分析服务
python3 ai_analysis.py输出:
✅ 工业AI分析服务已启动,每60秒自动分析一次 🤖 AI分析结果:xxxxxxx
第六步:Grafana 大屏添加 AI 文本面板
新增面板 → 选择 文本 / Stat 面板
数据源选
InfluxDBFlux 查询语句:
from(bucket: "plc_data") |> range(start: -10m) |> filter(fn: (r) => r._measurement == "ai_result") |> last()面板样式改成「文本展示」,就能实时显示 AI 智能分析文案
#第七步:后台常驻(断电自启)
用 nohup 后台运行,关掉终端也不停止:
nohup python3 ai_analysis.py > ai.log 2>&1 &
五、最终实现效果
1. 图形化监控大屏(Web 页面,电脑 / 平板 / 大屏电视均可访问)
- 打开浏览器输入服务器地址,直接看到生产线动态模拟图
- 设备运行:绿色;停机:灰色;报警:红色闪烁
- 所有参数实时跳动,曲线平滑更新
- 支持:放大、缩小、全屏、多设备同时查看
- 支持:手机 / 平板远程访问
2. 实时数据监控
- 生产线状态:运行 / 待机 / 故障
- 实时参数:温度、压力、转速、电流、电压
- 产量:当日产量、总产量、合格率
- 时长:已运行时间、停机时间
3. 历史趋势与报表
- 24 小时、7 天、30 天数据趋势图
- 自动生成日报、周报、月报
- 数据可导出 Excel
4. AI 智能分析(Ollama 大模型)
- 自动诊断:设备异常 → 给出可能原因
- 预测维护:“预计该电机 3 天后可能出现过热风险”
- 自然语言问答:
- 问:今天生产线产量怎么样?
- AI 答:今日产量 XXX,合格率 XXX,10 点出现一次温度过高报警…
- 异常总结:每日自动总结生产线问题
5. 告警系统
- 数据越限自动弹窗 + 声音提醒
- 告警记录自动保存
- 可对接邮件 / 企业微信推送
六、方案亮点
- 全开源、无版权、本地化部署(不上云,数据安全)
- 低代码 / 零代码部署,不用大量开发
- 实时性高(工业级 100ms 级刷新)
- AI 与工业监控深度融合
- 可无限扩展:加设备、加产线、加模型都很方便



